Apache Kafka
| Apache Kafka | ||
|---|---|---|
 | ||
| Información general | ||
| Tipo de programa | message-oriented middleware | |
| Autor | Neha Narkhede | |
| Desarrollador |
| |
| Lanzamiento inicial | 7 de noviembre de 2010 | |
| Licencia |
| |
| Información técnica | ||
| Programado en |
| |
| Versiones | ||
| Última versión estable | 3.7.026 de febrero de 2024 | |
| Lanzamientos | ||
| Java Message Service y Advanced Message Queuing Protocol | Apache Kafka | |
| Enlaces | ||
| Sitio web oficial Repositorio de código Seguimiento de errores | ||
[editar datos en Wikidata] | ||
Apache Kafka es un proyecto de intermediación de mensajes de código abierto desarrollado por LinkedIn y donado a la Apache Software Foundation escrito en Java y Scala. El proyecto tiene como objetivo proporcionar una plataforma unificada, de alto rendimiento y de baja latencia para la manipulación en tiempo real de fuentes de datos. Puede verse como una cola de mensajes, bajo el patrón publicación-suscripción, masivamente escalable concebida como un registro de transacciones distribuidas,[3] lo que la vuelve atractiva para las infraestructuras de aplicaciones empresariales.
El diseño tiene gran influencia de los registros de transacción.[4]
Historia
Apache Kafka fue originalmente desarrollado por la empresa Linkedin, la cual lo publicó como software libre a principios de 2011. En octubre de 2012 superó la etapa de incubación de la fundación Apache. En noviembre de 2014, varios ingenieros que trabajaron en el proyecto Kafka de Linkedin crearon una nueva empresa llamada Confluent enfocada en Kafka.[5]
Empresas que utilizan Kafka
La siguiente es una lista de empresas conocidas que utilizan o han utilizado Kafka:
- Cisco Sistemas[6]
- Daumkakao[7]
- Walmart[8]
- Netflix[9]
- Adidas[10]
- PayPal[11]
- Spotify[12]
- Uber[13]
- Spotify[12]
- Oracle[14]
- Twitter[15]
- Trivago[16]
- LinkedIn[17]
- Shopify[18]
- Betfair[19]
- Microsoft Azure[20]
Rendimiento de Kafka
Debido a su capacidad de escalar masivamente y a su uso en estructuras a nivel de aplicaciones empresariales, el seguimiento del rendimiento de Kafka se ha convertido en un tema cada vez más importante. Actualmente existen varias plataformas de código abierto, como Burrow de Linkedin, y plataformas de pago como Datadog,[3] que permiten hacer el seguimiento del desempeño de Kafka.
Arquitectura
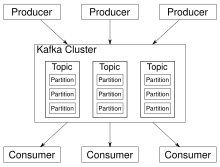
Kafka almacena mensajes de clave-valor que provienen de un número arbitrario de procesos llamados "productores". Los datos pueden dividirse en diferentes "particiones" dentro de diferentes "temas". Dentro de una partición, los mensajes se ordenan estrictamente por sus posiciones (la posición de un mensaje dentro de una partición), y se indexan y almacenan junto con una marca de tiempo. Otros procesos denominados "consumidores" pueden leer los mensajes de las particiones. Para el procesamiento de flujos, Kafka ofrece la API de flujos (Streams) que permite escribir aplicaciones Java que consumen datos de Kafka y escriben los resultados de vuelta a Kafka. Apache Kafka también funciona con sistemas de procesamiento de flujos externos como Apache Apex, Apache Beam, Apache Flink, Apache Spark, Apache Storm y Apache NiFi.
Kafka se ejecuta en un clúster de uno o más servidores (llamados brokers) y las particiones de todos los temas se distribuyen entre los distintos nodos del clúster. Además, las particiones se replican en varios brokers. Esta arquitectura permite a Kafka entregar flujos masivos de mensajes de forma tolerante a fallos y le ha permitido sustituir algunos de los sistemas de mensajería convencionales como Java Message Service (JMS), Advanced Message Queuing Protocol (AMQP), etc.
Desde la versión 0.11.0.0, Kafka ofrece escrituras transaccionales, que proporcionan un procesamiento de flujos de una sola vez utilizando la API de flujos (streams).
Kafka soporta dos tipos de temas: Regulares y compactados. Los temas regulares pueden configurarse con un tiempo de retención o un límite de espacio. Si hay registros que son más antiguos que el tiempo de retención especificado o si se supera el límite de espacio para una partición, Kafka puede eliminar los datos más antiguos para liberar espacio de almacenamiento. Por defecto, los temas se configuran con un tiempo de retención de 7 días, pero también es posible almacenar los datos indefinidamente.
En el caso de los temas compactados, los registros no caducan en función de los límites de tiempo o espacio. En su lugar, Kafka trata los mensajes posteriores como actualizaciones de mensajes más antiguos que tengan la misma clave y garantiza que nunca se borrará el último mensaje de una clave. Sin embargo, los usuarios pueden eliminar los mensajes por completo escribiendo un mensaje denominado tombstone con valor nulo para una clave específica.
Interfaces de Kafka
Hay cinco interfaces principales en Kafka:
- Producer API: Permite a una aplicación publicar flujos de registros.
- Consumer API: Permite a una aplicación suscribirse a temas y procesar flujos de registros.
- Connector API: Interfaz de importación/exportación para la conexión con sistemas de terceros.
- Streams API: Biblioteca Java para el procesamiento de flujos de datos, convirtiendo los flujos de entrada en salida y produciendo el resultado.
- Admin API: Se utiliza para gestionar los temas de Kafka, los brokers y otros objetos de Kafka.
Las interfaces de consumidor y productor se basan en el protocolo de mensajes Kafka y están desacopladas de la funcionalidad principal de Kafka. El protocolo de mensajes real de Kafka es un protocolo binario y, por lo tanto, permite que los clientes consumidores y productores se desarrollen en cualquier lenguaje de programación. Por lo tanto, Kafka no está vinculado al ecosistema JVM. En la Wiki de Apache Kafka se mantiene una lista de clientes no-Java disponibles.
API de conexión
Kafka Connect (o Connect API) proporciona una interfaz para cargar/exportar datos desde/a sistemas de terceros. Está disponible desde la versión 0.9.0.0 y se basa en la API de consumidores y productores. La API de Connect define la interfaz de programación que debe implementarse para construir un conector personalizado. Ya existen muchos conectores comerciales y de código abierto que pueden utilizarse. Sin embargo, Apache Kafka por sí mismo no proporciona ningún conector listo para la producción.
API de Streams
Kafka Streams (o Streams API) es una biblioteca Java para el procesamiento de flujos y está disponible a partir de la versión 0.10.0.0. La biblioteca permite desarrollar programas de procesamiento de flujos con estado que son escalables, flexibles y tolerantes a fallos.
Operador Kafka para Kubernetes
En agosto de 2019, se publicó un gestor para construir una plataforma Kafka nativa de la nube con Kubernetes.
Permite automatizar el despliegue de pods de los componentes del ecosistema Kafka (ZooKeeper, Kafka Connect, KSQL, Rest Proxy), monitorizar los SLA a través de Confluent Control Center o Prometheus, escalar Kafka de forma flexible, y gestionar las interrupciones y automatizar las actualizaciones continuas.
Compatibilidad de versiones
Hasta la versión 0.9.x, los brokers de Kafka sólo son compatibles con los clientes más antiguos.
A partir de la versión 0.10.0.0 de Kafka, los brokers son compatibles con versiones de clientes más recientes, aunque éstos sólo podrán utilizar las características que el broker soporte.
Para la API de Streams, la compatibilidad total comienza con la versión 0.10.1.0, por tanto una aplicación de Kafka Streams 0.10.1.0 no es compatible con versiones de brokers anteriores a 0.10.0.
Véase también
- Apache ActiveMQ
- Apache Samza
- StormMQ
- Apache Qpid
- Arquitecturas orientadas a servicios
Referencias
- ↑ «Mirror of Apache Kafka at GitHub]». github.com. Consultado el 6 de marzo de 2017.
- ↑ «Open-sourcing Kafka, LinkedIn's distributed message queue». Consultado el 27 de octubre de 2016.
- ↑ a b «Monitoring Kafka performance metrics». Datadog Engineering Blog. Consultado el 9 de junio de 2016.
- ↑ «The Log: What every software engineer should know about real-time data's unifying abstraction». LinkedIn Engineering Blog. Consultado el 9 de junio de 2016.
- ↑ Primack, Dan. «LinkedIn engineers spin out to launch 'Kafka' startup Confluent». fortune.com. Consultado el 9 de junio de 2016.
- ↑ «OpenSOC: An Open Commitment to Security». Cisco blog. Consultado el 3 de febrero de 2016.
- ↑ Doyung Yoon. «S2Graph : A Large-Scale Graph Database with HBase».
- ↑ «OpenSOC: Kafka Ecosystem on Walmart’s Cloud». Medium. Consultado el 15 de enero de 2019.
- ↑ Cheolsoo Park and Ashwin Shankar. «Netflix: Integrating Spark at Petabyte Scale».
- ↑ Error en la cita: Etiqueta
<ref>no válida; no se ha definido el contenido de las referencias llamadasAdidas - ↑ Shibi Sudhakaran of PayPal. «PayPal: Creating a Central Data Backbone: Couchbase Server to Kafka to Hadoop and Back (talk at Couchbase Connect 2015)». Couchbase. Archivado desde el original el 17 de septiembre de 2016. Consultado el 3 de marzo de 2016.
- ↑ a b Josh Baer. «How Apache Drives Spotify's Music Recommendations».
- ↑ «Stream Processing in Uber». InfoQ. Consultado el 6 de diciembre de 2015.
- ↑ Error en la cita: Etiqueta
<ref>no válida; no se ha definido el contenido de las referencias llamadasOracle - ↑ Error en la cita: Etiqueta
<ref>no válida; no se ha definido el contenido de las referencias llamadasTwitter - ↑ Error en la cita: Etiqueta
<ref>no válida; no se ha definido el contenido de las referencias llamadasTrivago - ↑ Error en la cita: Etiqueta
<ref>no válida; no se ha definido el contenido de las referencias llamadasLinkedIn - ↑ «Shopify - Sarama is a Go library for Apache Kafka».
- ↑ «Exchange Market Data Streaming with Kafka». Archivado desde el original el 27 de enero de 2016. Consultado el 9 de junio de 2016.
- ↑ George, Sam (5 de diciembre de 2016). «Kafka Connect for Azure IoT Hub» (html). Microsoft (en inglés). Archivado desde el original el 13 de julio de 2017. Consultado el 12 de marzo de 2019.
 Datos: Q16235208
Datos: Q16235208 Multimedia: Apache Kafka / Q16235208
Multimedia: Apache Kafka / Q16235208








